The Universal AI Inference Engine
Deploy your models on any hardware, from GPU to NPU, with peak performance.
Inference Engine, Built with Optimal Technology
The Yetter Inference Engine combines model lightening, serving framework optimization, and low-level technologies that leverage each hardware's unique advantages. We return the full cost-efficiency benefits from our powerful and lightweight optimization stack to you
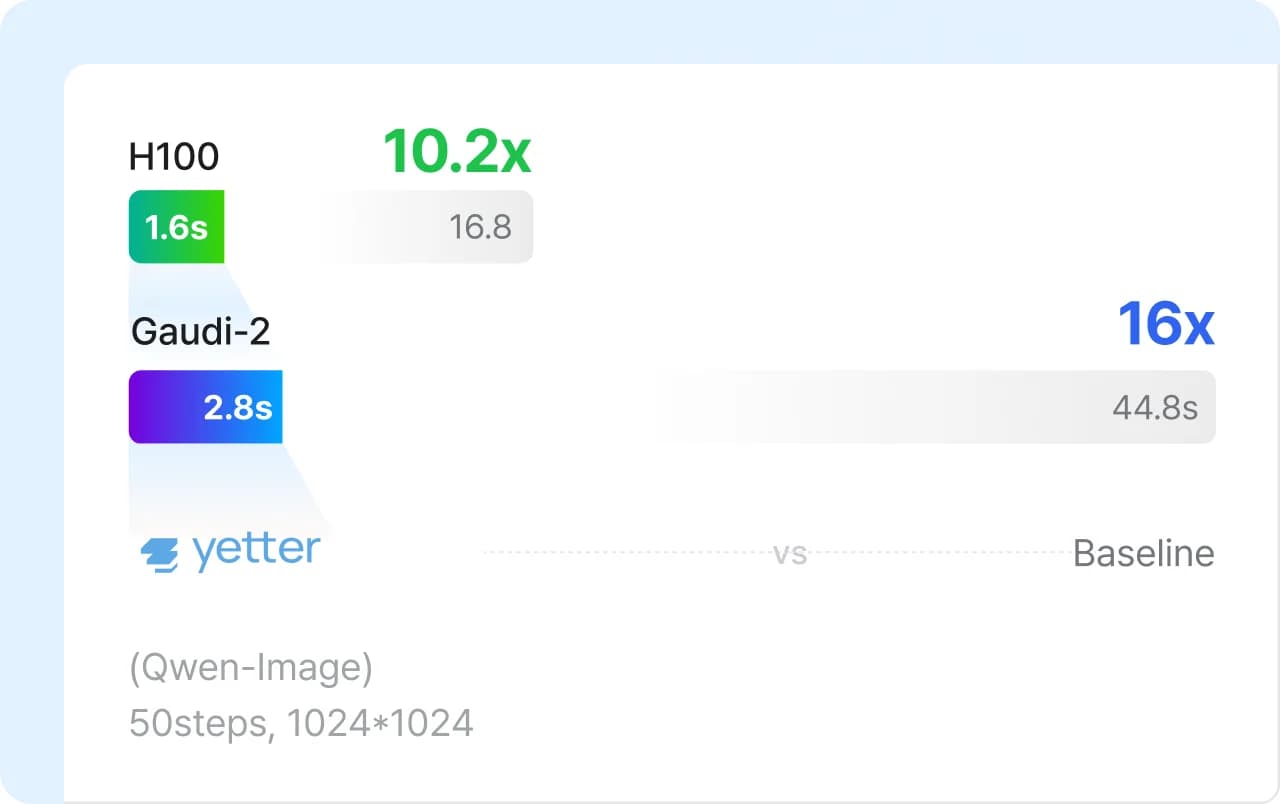
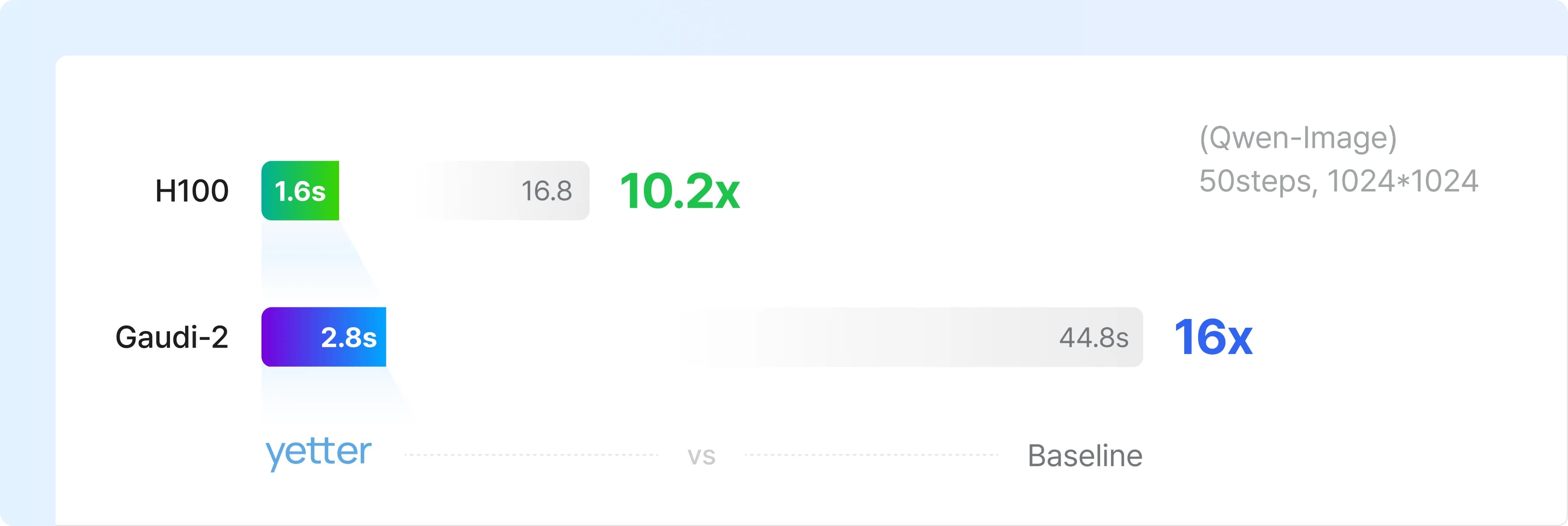








A Tech Stack That Crosses HW/SW Frameworks


Yetter goes beyond simple model serving by meticulously analyzing the performance-cost curves of various hardware, like GPUs and NPUs, to precisely tune our software framework. This process allows us to find the optimal balance between quality, cost, and speed.
Empower Your AI Infrastructure
API Users
Leverage Yetter.ai's fast and efficient API to build innovative services with generative images and videos. Our diversified technology stack and supply chain, spanning both GPUs and NPUs, ensure service stability and mitigate risks.
Building New NPUs
For an NPU under development to be practically used in the field, a diverse software stack for running generative AI is necessary. Yetter expands the capabilities of NPUs with its understanding of both hardware and software. Due to the nature of NPUs, understanding the hardware is paramount.
CSPCloud Service Provider
Diversifying servers with NPUs is an important step for advancing cloud services. To enable effective cloud use by end-users, it is necessary to demonstrate NPU capabilities and their practical application. Generative AI can be accelerated on NPUs with the Yetter inference engine, with GPU acceleration also supported.